Back
Nov 22, 2024

Quinn Grasteit

In the world of document processing, PDFs remain both ubiquitous and challenging. While numerous tools exist for PDF text extraction, anyone who's worked extensively with document processing knows the frustration of inconsistent results, especially when dealing with complex layouts, tables, and embedded images. This post details our journey from traditional PDF parsing to a more robust solution using multimodal AI models, and the surprising improvements we discovered along the way.
The Challenge: When Traditional PDF Parsing Falls Short
Let's be clear upfront: tools like PyPDFLoader and LlamaParse are excellent choices for text-heavy documents. If you're processing research papers, contracts, or other primarily text-based PDFs, these parsers are fast, efficient, and should be your go-to solution.
The real challenges emerge when processing PDFs with complex tables, embedded images, mixed layouts, or documents where spatial relationships between elements matter. These scenarios often lead to frustrating results with traditional parsing methods.
A Real-World Example
Let's look at a real-world example from a public health surveillance report that illustrates these challenges:
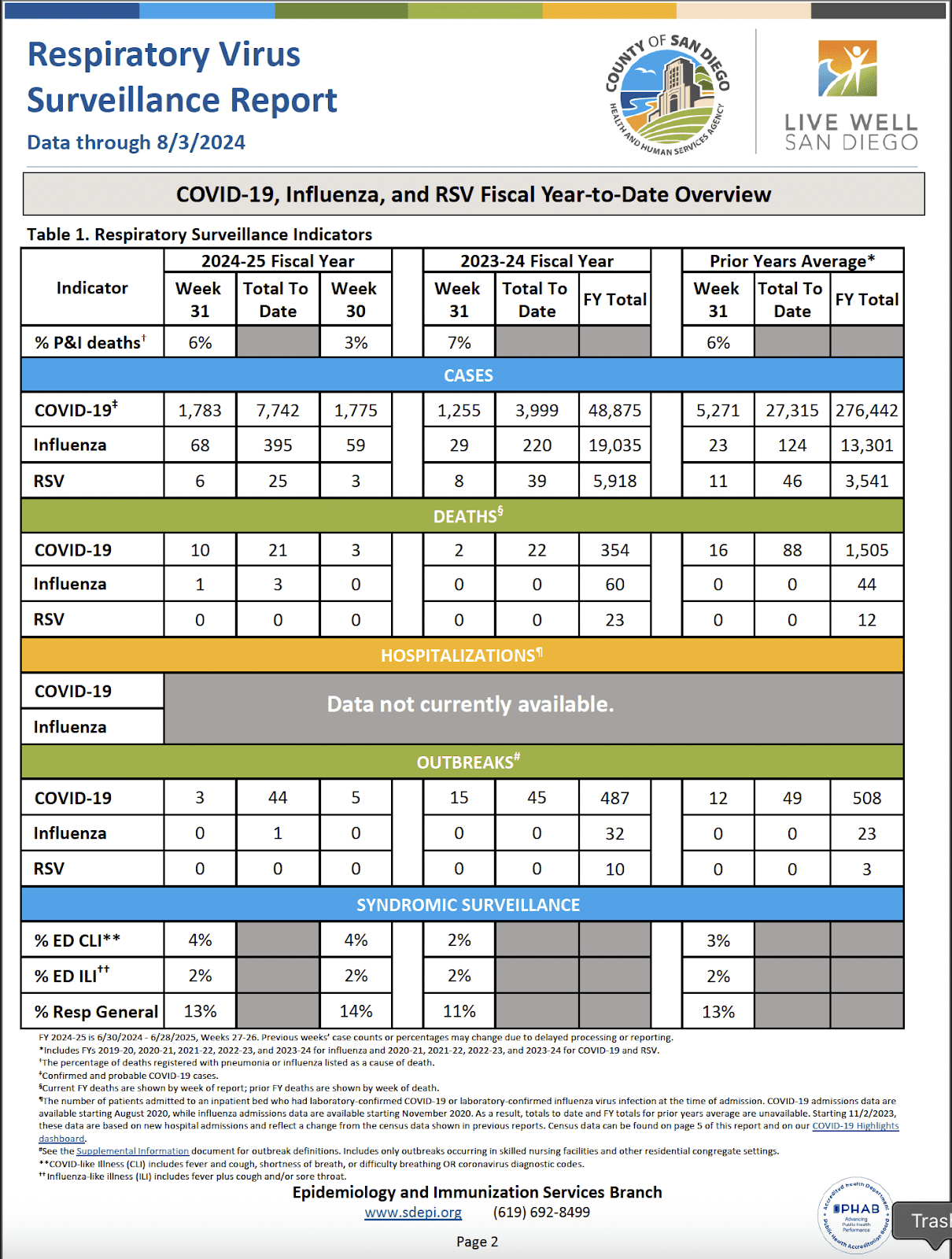
Traditional Parser Output
When examining this output, several problems become apparent. The parser lost the table's structure and relationships, mixed section headers with data, and dropped critical metadata. More concerning, it failed to maintain data alignment across fiscal years and lost important formatting elements like conditional data availability notices.
Multimodal Parser Output
Notice how the multimodal model:
Preserved the complex multi-level table structure
Maintained section headers and their relationships to data
Captured and properly formatted footnotes
Preserved data alignment across different time periods
Handled conditional formatting ("Data not currently available")
Maintained the hierarchical structure of the report
Correctly associated symbols (†, §, ¶) with their corresponding footnotes
This dramatic improvement in output quality illustrates why we decided to pursue a multimodal approach for complex documents. Let's explore how we achieved these results.
The Pivot: Treating PDFs as Images
Our breakthrough came from a seemingly counterintuitive approach: converting PDFs to images and using multimodal models for extraction. This approach preserves spatial context by treating each page as an image, maintaining crucial relationships between elements that often get lost in traditional parsing.
Instead of managing separate workflows for text, tables, and images, we now have a single pipeline that understands all elements in context. This unified approach has transformed how we handle complex documents.
The multimodal models excel at understanding visual hierarchies and relationships. They can recognize table structures and their cell relationships, connect image captions with their corresponding images, and maintain the proper relationship between headers and content. Even footnotes and their references remain intact throughout the process.
Our implementation followed three key phases:
PDF to Image Conversion
The first step involved converting PDF pages to high-resolution images. While this might seem like a step backward, it proved crucial for maintaining the fidelity of both text and visual elements. The key was finding the right balance between image quality and file size. Key providers in this space are pdf2image and PyMuPDF.
Multimodal Model Integration
With our images prepared, we integrated a multimodal model as our unified interpreter. This model reads text with proper context, understands table structures, and maintains document hierarchy—all while interpreting images in relation to their surrounding content. Critical to our success was the use of structured XML prompts to guide the model's attention and output format—a technique we explore in depth in our companion post "Enhancing AI Interactions: The Strategic Use of XML Tags in Prompts". This structured approach ensures consistent, high-quality extraction across diverse document types.
Structured Output Engineering
Perhaps most importantly, we developed a system for consistent structured output. This ensures clean table representations, maintains proper document hierarchy, and preserves relationships between elements—all while maintaining consistent formatting across different document types.
Performance and Results
Our document processing solution leverages both cloud and on-premises deployments to meet diverse customer needs.
Cloud Implementation with Amazon Bedrock
We utilize Amazon Bedrock's Llama 3.2 Vision and Claude 3.5 Sonnet models, enabling rapid processing without infrastructure overhead. This approach offers sub-second latency, automatic scaling, and pay-per-use pricing—making it ideal for organizations with varying workload demands.
On-Premises Solutions for Air-Gapped Environments
For customers requiring complete data isolation, we support local deployment using Ollama with Llama 3.2 Vision. While this requires dedicated GPU resources, it provides full data sovereignty and security control.
Our testing shows substantial improvements across both deployments:
Traditional parsing: 98% accuracy for text-only documents
Multimodal processing: 92% accuracy for complex tables, 89% for mixed layouts
Processing time: 0.8-2.5 seconds per page, depending on complexity
Manual review requirements reduced by 85%
Technical Considerations
The system maintains consistent processing boundaries regardless of deployment:
Maximum page resolution: 4096x4096 pixels
Document size limit: 100MB
Batch processing: up to 500 pages per document
Both cloud and on-premises deployments handle specialized content including handwritten text, complex equations, and small fonts through targeted pre-processing steps.
Quality and Scalability
Our operational framework ensures reliable processing through:
Automatic model selection based on content type
Confidence scoring for extracted content
Dynamic resource allocation (cloud) or efficient GPU utilization (on-premises)
Intelligent error handling and correction
The choice between cloud and on-premises deployment primarily depends on security requirements and processing volume rather than capability differences.
Choosing the Right Approach
Through our experience, we've learned that success lies in selecting the right tool for each scenario:
Traditional Parsers Work Best For: Simple, text-based documents where speed and efficiency matter most. Think research papers, standard contracts, or text-heavy reports.
The Multimodal Approach Shines When: You're dealing with complex layouts, meaningful images, or documents where spatial relationships are crucial. This method particularly excels with forms, technical documentation, and mixed-content layouts.
The Ignite and Warp Pipe Implementation
Our solution comes to life through two key components: the Ignite GenAI platform and our Warp Pipe data ingestion process. Together, they form a comprehensive document processing system.
Ignite: Powering Intelligent Processing
Ignite serves as the brain of our operation, bringing together multimodal capabilities with precise data extraction. The platform continuously learns from new document types, adapting its approach while maintaining consistent output quality. Quality assurance checks run automatically, ensuring reliable results without constant manual oversight.
Warp Pipe: Streamlined Data Flow
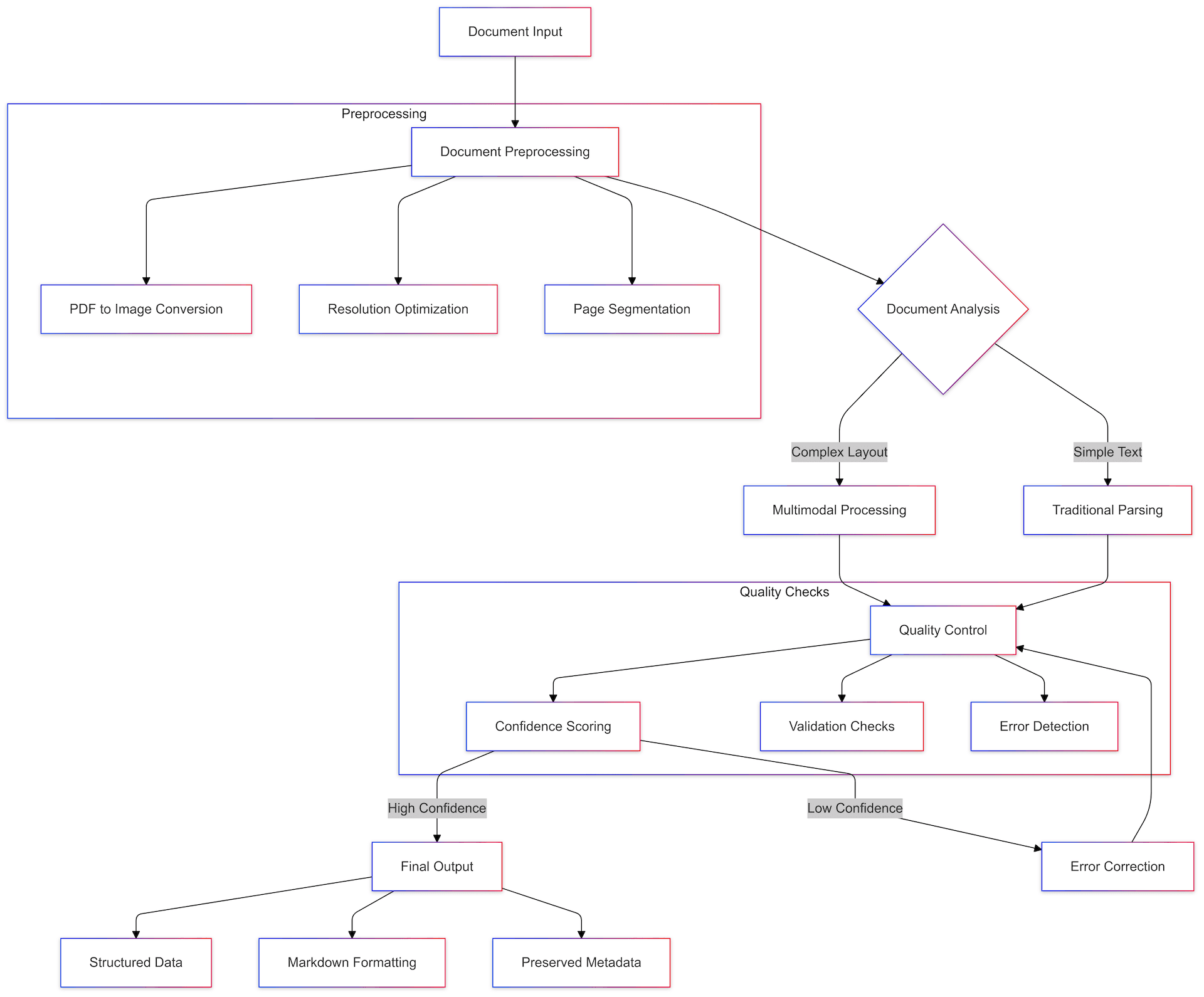
Document preprocessing forms the foundation of Warp Pipe's operation. The system automatically converts PDFs to high-quality images while optimizing resolution for model processing. Advanced page segmentation and analysis ensure we capture every detail.
Our intelligent routing system determines the optimal processing path for each document. By analyzing document characteristics, it chooses between traditional parsing and multimodal processing, maximizing efficiency while maintaining quality. High-volume workloads benefit from parallel processing capabilities that scale with demand.
Data Extraction and Quality Control
Warp Pipe maintains strict control over data quality throughout the extraction process. The system produces consistent markdown formatting while preserving document metadata. Automated validation checks analyze extracted data, applying confidence scoring to each element. When potential issues arise, our error detection workflows trigger appropriate correction mechanisms.
Measurable Impact
The implementation of Ignite and Warp Pipe has transformed our document processing capabilities. We've seen dramatic improvements across several key metrics:
Traditional parsing rules have decreased by over 90%, significantly reducing maintenance overhead. Document processing accuracy has improved substantially, particularly for complex layouts. Perhaps most importantly, the time required to handle new document types has decreased dramatically, while maintaining consistent data structure across all processed documents.
Manual intervention, once a significant bottleneck, has been reduced to a fraction of its former level. This automation not only improves efficiency but also reduces the potential for human error in the extraction process.
Looking Ahead
The success of our multimodal approach opens exciting possibilities for the future of document processing. We're exploring enhanced capabilities for handling increasingly complex document types, including:
Interactive documents with dynamic elements
Multi-language documents with mixed character sets
Documents with complex conditional formatting
Legacy documents with deteriorated quality
Our team continues to refine the balance between processing power and efficiency, always working toward the goal of more natural document understanding. The future of document processing lies not in more sophisticated parsing rules, but in enabling AI to comprehend documents as humans do.
Conclusion
The journey from traditional PDF parsing to our current multimodal approach has taught us valuable lessons about document processing. While converting PDFs to images might seem counterintuitive, the power of multimodal models has proven transformative. By enabling AI to understand documents holistically—combining visual and textual information—we've created a more robust and reliable processing pipeline.
This approach has significantly improved data extraction reliability, preserved document context more effectively, and reduced the need for document-specific parsing rules. Most importantly, it has opened new possibilities for handling even more complex document types in the future.
Remember, sometimes the most effective solution isn't about parsing data more cleverly, but about enabling AI to understand documents more naturally. The key lies in finding the right balance between technological capability and practical application.
Ready to transform your document processing? Contact the Fireflower AI team to see Ignite in action and discover how our solution can work for your specific needs.
Quinn Grasteit
Share this post